


达内java培训专家:说说什么是数据挖掘
日期:2017-01-11 / 人气: / 来源:本站
说了那么久大数据,相信小伙伴们已经有了初步的认知,本文达内java培训(java.tedu.cn)专家给大家来点实例,为大家介绍一下什么是数据挖掘:
何为数据挖掘?
数据挖掘就是指从数据中获取知识。
好吧,这样的定义方式比较抽象,但这也是业界认可度最高的一种解释了。对于如何开发一个大数据环境下完整的数据挖掘项目,业界至今仍没有统一的规范。说白了,大家都听说过大数据、数据挖掘等概念,然而真正能做而且做好的公司并不是很多。
笔者本人曾任职于A公司云计算事业群的数据引擎团队,有幸参与过几个比较大型的数据挖掘项目,因此对于如何实施大数据场景下的数据挖掘工程有一些小小的心得。但由于本系列博文主要是结合传统数据挖掘理论和笔者自身在A云的一些实践经历,因此部分观点会有较强主观性,也欢迎大家来跟我探讨。
数据挖掘背后的哲学思想
在过去很多年,首要原则模型(first-principle models)是科学工程领域最为经典的模型。
比如你要想知道某辆车从启动到速度稳定行驶的距离,那么你会先统计从启动到稳定耗费的时间、稳定后的速度、加速度等参数;然后运用牛顿第二定律(或者其他物理学公式)建立模型;最后根据该车多次实验的结果列出方程组从而计算出模型的各个参数。通过该过程,你就相当于学习到了一个知识---某辆车从启动到速度稳定行驶的具体模型。此后往该模型输入车的启动参数便可自动计算出该车达到稳定速度前行驶的距离。
然而,在数据挖掘的思想中,知识的学习是不需要通过具体问题的专业知识建模。如果之前已经记录下了100辆型号性能相似的车从启动到速度稳定行驶的距离,,那么我就能够对这100个数据求均值,从而得到结果。显然,这一过程是是直接面向数据的,或者说我们是直接从数据开发模型的。
这其实是模拟了人的原始学习过程---比如你要预测一个人跑100米要多久时间,你肯定是根据之前了解的他(研究对象)这样体型的人跑100米用的多少时间做一个估计,而不会使用牛顿定律来算。
数据挖掘的起源
由于数据挖掘理论涉及到的面很广,它实际上起源于多个学科。如建模部分主要起源于统计学和机器学习。统计学方法以模型为驱动,常常建立一个能够产生数据的模型;而机器学习则以算法为驱动,让计算机通过执行算法来发现知识。仔细想想,"学习"本身就有算法的意思在里面嘛。
然而数据挖掘除了建模外,还有不少其他要做的工作(本文后面会一一讲到),因此涉及到不少其他知识,如下图所示:
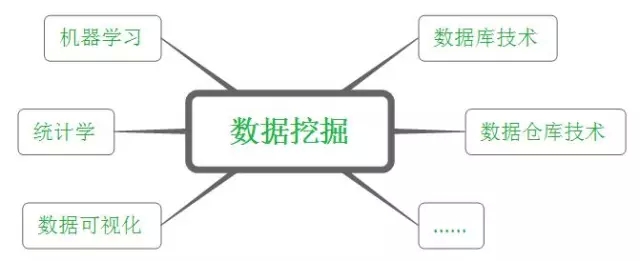
数据挖掘的基本任务
数据挖掘的两大基本目标是预测和描述数据。其中前者的计算机建模及实现过程通常被称为监督学习(supervised learning),后者的则通常被称为无监督学习(supervised learning)。往更细分,数据挖掘的目标可以划分为以下这些:
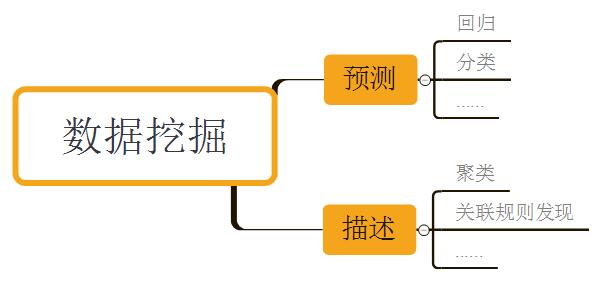
预测主要包括分类-将样本划分到几个预定义类之一,回归-将样本映射到一个真实值预测变量上;描述主要包括聚类-将样本划分为不同类(无预定义类),关联规则发现-发现数据集中不同特征的相关性。本系列其他文章将会分别对这些工作深入进行讲解,如果读者是第一次接触这些概念请不要纠结。
数据挖掘的基本流程
从形式上来说,数据挖掘的开发流程是迭代式的。开发人员通过如下几个阶段对数据进行迭代式处理:
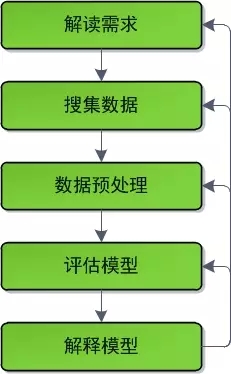
其中,
1.解读需求
绝大多数的数据挖掘工程都是针对具体领域的,因此数据挖掘工作人员不应该沉浸在自己的世界里YY算法模型,而应该多和具体领域的专家交流合作以正确的解读出项目需求。这种合作应当贯穿整个项目生命周期。
2.搜集数据
在大型公司,数据搜集大都是从其他业务系统数据库提取。很多时候我们是对数据进行抽样,在这种情况下必须理解数据的抽样过程是如何影响取样分布,以确保评估模型环节中用于训练(train)和检验(test)模型的数据来自同一个分布。
3.预处理数据
预处理数据可主要分为数据准备和数据归约两部分。其中前者包含了缺失值处理、异常值处理、归一化、平整化、时间序列加权等;而后者主要包含维度归约、值归约、以及案例归约。后面两篇博文将分别讲解数据准备和数据归约。
4.评估模型
#p#分页标题#e#确切来说,这一步就是在不同的模型之间做出选择,找到最优模型。很多人认为这一步是数据挖掘的全部,但显然这是以偏概全的,甚至绝大多数情况下这一步耗费的时间和精力在整个流程里是最少的。
5.解释模型
数据挖掘模型在大多数情况下是用来辅助决策的,人们显然不会根据"黑箱模型"来制定决策。如何针对具体环境对模型做出合理解释也是一项非常重要的任务。
数据挖掘的工程架构
回到本文开头提到的那个问题,“如何开发一个大数据环境下完整的数据挖掘项目?”。这个问题每个公司有自己的答案,这里仅以A公司的情况进行介绍。
在A公司的数据引擎团队中,主要人员分成A、B、C、D四个大组。这四个大组的分工非常明确,如下图所示:
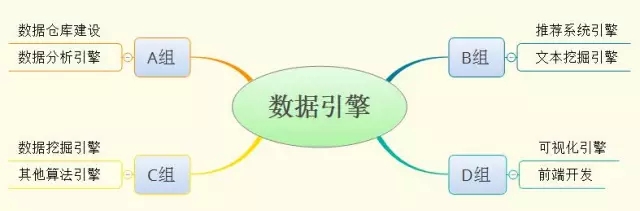
图中的这些个数据引擎架构在一个基于维度建模的云数据仓库之上,并对上层应用提供算法支撑、推荐支撑、可视化支撑等等。这里也能看出A公司的数据挖掘工程架构主要由三大块组成:底层数据仓库、中间数据引擎、高层可视化/前端输出。很多小伙伴问我,你是一名数据挖掘工程师呀,可为什么你前面的博文都是数据仓库和数据可视化呢?我想如果他们看到这里想必不会有此疑问了:)。
至于这些引擎的具体作用、开发方法,体系结构等则由于涉及公司秘密不能深入细说,请各位读者见谅。
小结
数据挖掘涵盖的面非常大,本文仅旨在让读者对数据挖掘有一个感性的认识。关于什么是数据挖掘如果你还不清楚的话也不要纠结,你可以到达内java大数据试听课程学学看。你一定能有所收获并会最终发现:数据挖掘是一门非常有趣的学问,比单纯的写代码要有意思多了。
8月java大数据试听课程最后一天,名额不多,欢迎通过微信公众号:“达内java大数据培训”报名,还可以留言给达内java培训(java.tedu.cn)专家,听听他们的意见,开始你的学习旅程吧!
作者:中立达资产评估
推荐内容 Recommended
- 山东高速股份有限公司第四届董事会第七十二次04-10
- 长宁区二手车收购交易市场「颖荣二手回收公司04-03
- 版权评估为金融与文化架桥 10部剧版权=近亿元03-26
- 广州市知识产权质押融资风险赔偿基金开启“广03-08
- 普洱日报数字报01-31
- 市房地产交易大厅已评估事项实现率100%01-16
相关内容 Related
- 无形资产评估之非专利技术价值评估需要搜集哪11-26
- 非专利技术可以出资吗?有什么要求?11-26
- 康盛股份:拟以资产置换及支付现金方式购买资04-17
- 我国首个国家级知识产权评估认证中心成立04-16
- 山东同大海岛新材料股份有限公司首次公开发行股票并在创业板上市招股意向书04-15
- 山东高速路桥集团股份有限公司股票恢复上市公告书04-14