


NoSQL选型及HBase案例详解
日期:2016-07-01 / 人气: / 来源:本站
从 NOSQL的类型到 常用的产品,我们已经做过很多关于NoSQL的文章,今天我们从国内著名的互联网公司及科研机构的实战谈一下NoSQL数据库。
NoSQL一定程度上是基于一个很重要的原理—— CAP原理提出来的。传统的SQL数据库(关系型数据库)都具有ACID属性,对一致性要求很高,因此降低了A(availability)和P(partion tolerance)。为了提高系统性能和可扩展性,必须牺牲C(consistency)。
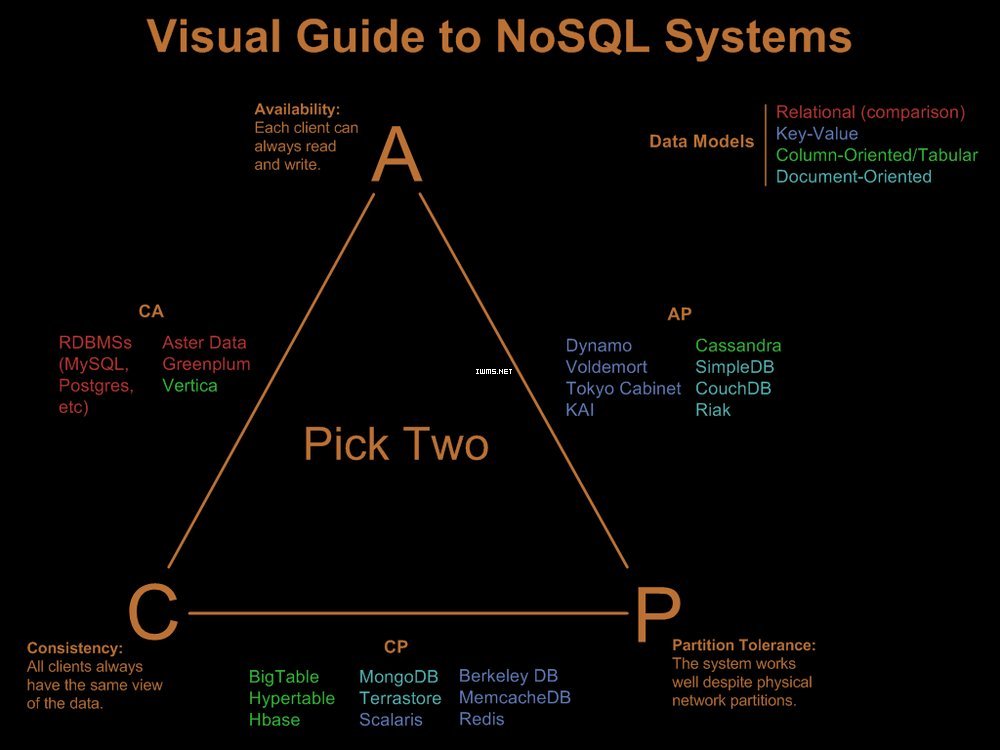
依据CAP理论,从应用的需求不同,数据库的选择可从三方面考虑:
考虑CA,这就是传统上的关系型数据库(RDBMS)。
考虑CP,主要是一些Key-Value数据库,典型代表为Google的Big Table,将各列数据进行排序存储。数据值按范围分布在多台机器,数据更新操作有严格的一致性保证。
考虑AP,主要是一些面向文档的适用于分布式系统的数据库,如Amazon的Dynamo,Dynamo将数据按key进行Hash存储。其数据分片模型有比较强的容灾性,,因此它实现的是相对松散的弱一致性——最终一致性。
SurDoc是书生公司自主创新的电子文档云服务平台,它支持云服务和移动终端,基于国际标准UOML,是目前全球唯一能让用户无需安装Office、PDF或其他软件就能阅读所有格式文档的产品。书生网北京书生软件公司副总裁兼CTO金友兵介绍了SurDoc开发过程中数据库的NoSQL选型及使用经验。
首先,金友兵认为数据模型是数据库选型中首先要考虑的问题,SurDoc中主要有三类数据:
用户自己上传的文档,采用分布式文件系统存储
用户自己的文档信息库,采用关系数据库MySQL。
文档本身的基本信息、分片信息及存储位置等,采用NoSQL数据库。这部分数据的主要特点是数据量大并且数据结构比较简单。这部分数据要保证CAP原理中的AP。
NoSQL数据库的选型需要考虑以下几方面:
数据模型及操作模型:应用层数据模型是行、对象还是文档型的呢?系统是否能支持统计工作?
可靠性:更新数据时,新的数据是否立刻写到持久化存储中去了?新的数据是否同步到多台机器上了?
扩展性:你的数据量有多大,单机是否能容下?读写量要求单机是否能支持?
分区策略:考虑对扩展性,可用性或者持久性的要求,是否需要一份数据被存在多台机器上?是否需要知道数据在哪台机器上。
一致性:数据是否被复制到了多台机器上,这些分布在不同点的数据如何保证一致性?
事务机制:业务是否需要ACID的事务机制?
单机性能:如果持久化将数据存在磁盘上,需求是读多还是写多?写操作是否会成为磁盘瓶颈?
负载可评估:是否支持负载监控?
初期MemcacheDB实践
优点:
MemcacheDB利用Berkeley DB的持久化存储机制和异步主辅复制机制,使memcached具备了事务恢复能力、持久化能力和分布式复制能力,
非常适合于需要超高性能读写速度,但是不需要严格事务约束,能够被持久化保存的应用场景。
吞吐量大,读写速度优秀,兼容memcached接口
缺点:
只支持单向的主从复制方式,可用性差。由于存在命中率问题,有时无法正确读,横向扩展比较困难。
Redis实践
数据库也具有类似于MemcacheDB的问题,新浪微博采用的NoSQL数据库是Redis,Redis的优点是性能很高。
TokyoTyrant实践
优点:
读写速度和并发性能比较优秀,支持Memcached协议,而且支持通过双主复制实现高可用性。
缺点:
需要通过客户端实现数据分布,增删节点时的数据重分布较难实现。与Surdoc采用的分布式文件系统不能很好的配合,不太适合互联网应用。
CouchBase实践
优点:
吞吐量极高,读写速度极快,支持memcached协议
实测三个Couchbase节点可以达到12000以上的ops
缺点:
采用缓存全部key的策略,需要大量内存;节点宕机时failover过程有不可用时间,并且有部分数据丢失的可能;在高负载系统上有假死现象
设计过程中应该尽量减少Key的位数,实际运营了一段时间,出现故障的概率较高。
最终选择——Amazon Dynamo的开源实现Riak
优点:
完全的Dynamo实现,数据总是可写
高可用:设计上天然没有单点,每个实例由一组节点组成,从应用的角度看,实例提供I/O 能力。一个实例上的节点可能位于不同的数据中心内,这样一个数据中心出问题也不会导致数据丢失。
可通过增加节点提高集群吞吐量
后端存储采用levelDB,不需要大量内存
实测三个Couchbase节点可以达到5000左右的ops
缺点:
不支持memcached协议,需要修改现有代码;没有完善的监控系统,需要自行实现
Riak技术要点:
数据定位使用一致性哈希
Vector lock,允许数据的多个备份存在多个版本,提高写操作的可用性(用弱一致性来换取高的可用性)
容错:Sloppy Quorum, hinted handoff, Merkletree
网络互联: Gossip-based membership protocol ,一种通讯协议,目标是让节点与节点之间通信,实现去中心化
此外,Riak还具有执行Mapreduce操作的能力:
Map过程在各个物理节点上并行的执行
Reduce过程在提交MapReduce的节点上并行执行
支持以Javascript和Erlang代码编写MapReduce过程
基于SurDoc系统的数据模型及各种应用场景,金友兵介绍的NoSQL数据库大多数保证CAP原理中的AP,我们上面已经提到还有另一类以Big Table为代表的NoSQL数据库,人人游戏大数据研究组数据科学家林述民为我们介绍了Big Table的开源实现——HBase。
首先,根据官方定义,HBase并不是一个数据库:
Apache HBase? is the Hadoop database, a distributed, scalable, big data store.
它是BigTable的开源实现,HBase用了大量的词汇替代以前Google论文中的设计理念或者是设计概念,如果想深入了解HBase工作原理,一定要把这些词从原文上找到出处或者是意义。以下是一些对应关系:

在整个Hadoop生态系统中,它位于HDFS的上层。 #p#分页标题#e#

上图是整个HBase的总体架构图,大概分为三个层次:最上面就是访问HBase的一个客户端,中间相当于RegionServer,可以管理最下层的分布式文件系统,标准的配置是HDFS。三个层次之间是解耦的,好多人对此存在一些误区。
Rowkey设计是使用HBase时最重要的一个环节,接下来林述民以通过对比NoSQL数据库和关系型数据库,说明了HBase的Rowkey设计会怎样影响系统的性能。
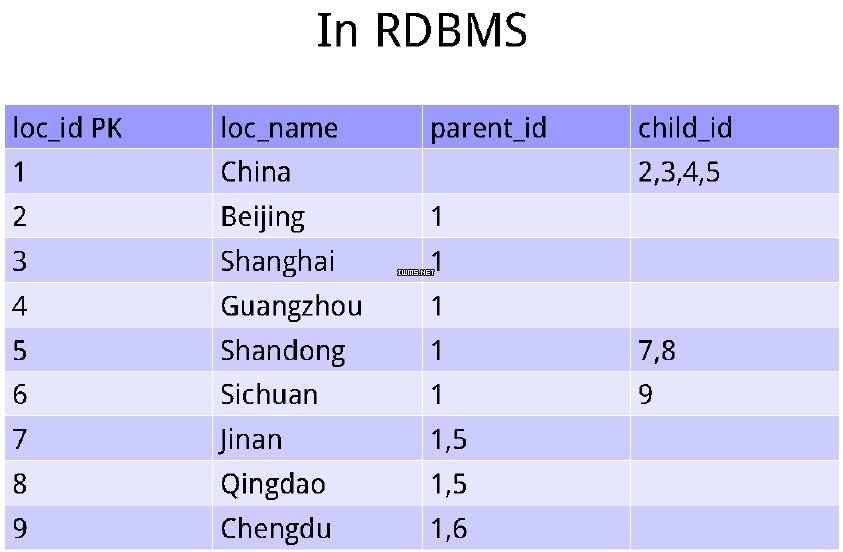
例1:稀疏矩阵结构
比如我国的省市结构是一个典型的树型结构:中国下面有北京、上海直辖市,还有广州、山东这样一些省,省下面还有市。采用传统的关系型数据库存储是以下的方式:
用HBase设计这样的存储结构是这样做的:
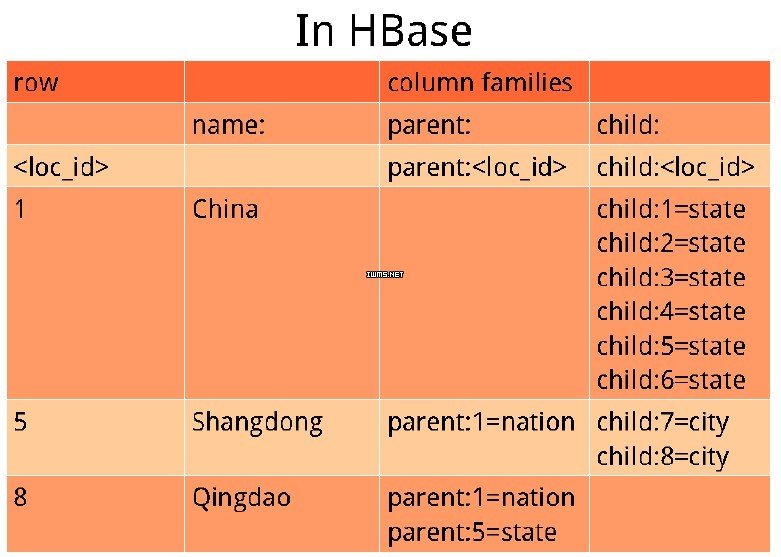
可能还是用这个主键标识一个地区,那边还是有两个列,但不再用打逗号的方式来存它的父节点或者子节点。因为HBase中的列可以在生产过程中定义,不需要预先定义好。对于一些稀疏的矩阵结构,这种存储方式的优势很明显。
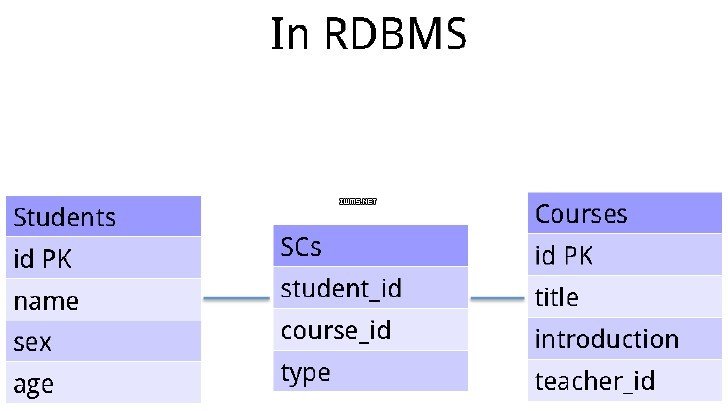
例2:多对多关系
比如学校的选课系统,一个学生可以选很多门课程,同时每门课程也可以有好多学生去选,是一个典型的多对多关系。传统的关系型数据库存储:
HBase存储方式:
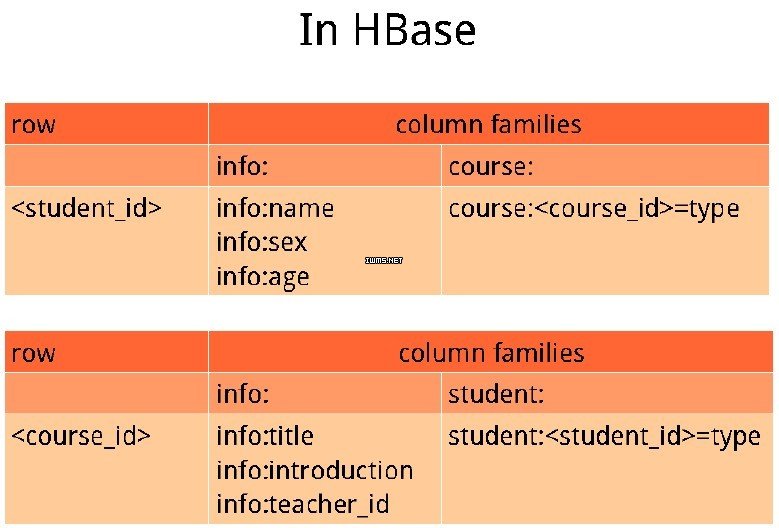
这样设计,可以实现每条记录的动态扩展,很匹配真实的业务场景。
例3:Key代替索引
比如人人的广告系统,一天就有十亿条记录。这些记录怎样存储下来呢?一种方式就是直接放到文件系统,包括用户ID是什么,名字是什么,什么时候做了什么事。为了便于查询,就必须要做索引,会降低性能。
在HBase中是这样设计的:

表中左列是Key,第一部分是用户标识,第二部分是用户操作时间,第三部分是事件ID(靠前的在检索时更有优势,在设计时可以利用这点进行优化)。检索的时候,首先找到这个Key在哪台服务器上,客户端再直接去那台服务器中做一个很小范围的检索。存的时候也通过这个ID存到不同服务器上面,所以吞吐量非常大。
例4:热点问题
用户的社交关系存储,大型互联网公司都会遇到这个问题。类似于前面的例子,在HBase中可以这样设计: #p#分页标题#e#
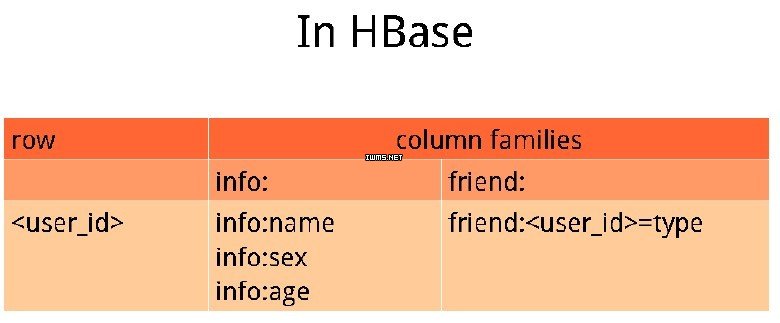
但是这种设计会存在热点问题,比如某个人可能有十万个好友,一旦查询到这个人,整个服务器就死掉了。所以这个设计可以改进一下,可以把friend那一列的内容也放到Key中,这张表就变成两两之间的关系,热点问题就可以解决了。
例5:关联概念
接下来是一个数据分析案例,业务场景是这样的:假设有一个搜索引擎每天采集用户大量的搜索数据,怎样知道用户总是把哪些概念放在一起搜索?在HBase中可以得到这样的逻辑关系,其中T(n)是搜索关键词:
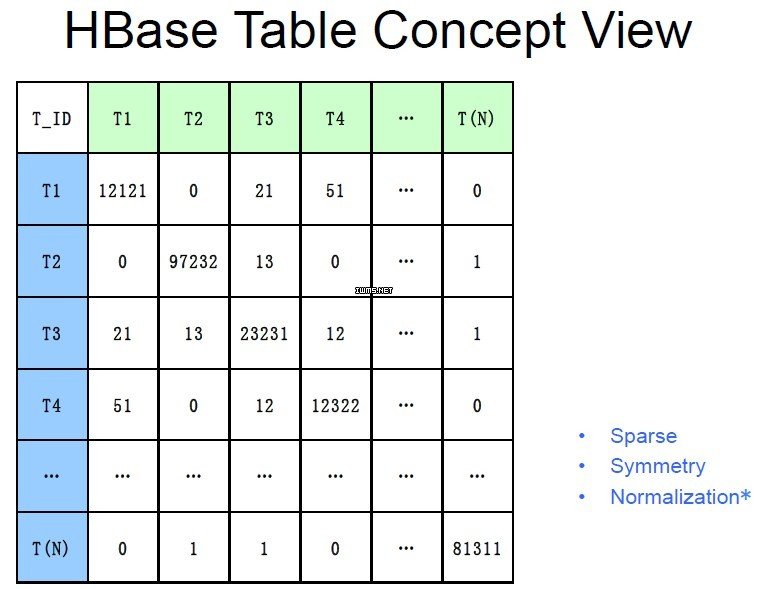
这种逻辑关系在关系型数据库中是无法设计的,其存储优势在于列弹性,只有被一起检索过的关键词才会存储下来,这也是传统意义上列存储的优势。
通过这几个案例可以知道在HBase中需要注意以下几个问题:
避免热点问题,分布式就怕不均匀。
HBase有分割的概念。一台服务器如果存储数据量很大,会把大表或者小表分成两个更小的表,放在其他服务器上,所以尽量要减少这些分割。
珍惜每一个字节,可以节约资源,降低风险,而且可以减少I/O,使这个系统做到最佳。
HBase没有外键,也没有join和跨表的transaction。
接下来,中国科学院信息工程研究所副研究员王树鹏为我们分享了“新型NoSQL大数据管理系统(BDMS)开发和使用交流”。王树鹏介绍说他接触的项目多数是非互联网的应用,比如安全、交通行业。这些行业目前也面临着大数据的考验,但是当前很多流行的NoSQL数据库对于他们来说并不适用,所以他们自主研发了一个NoSQL数据库管理系统。
设计目标
系统具有高可扩展性:可通过增加节点线性
支持复杂数据类型统一存储管理:结构化数据、半结构化数据及非结构化数据;文本数据、多媒体数据;针对多种类型业务数据进行统一组织管理和处理
支持多样化的访问类型,访问接口标准化:检索、统计分析、关联处理及深入挖掘;需要对多种业务数据进行关联综合分析;提供标准的DDL、DML操作语法,支持JDBC、ODBC等操作接口;对数据检索、统计、分析处理的实时性要求很高;检索要求秒级响应;跨域检索访问

上图是整个系统的框架,其中数据库管理平台的结构如下:
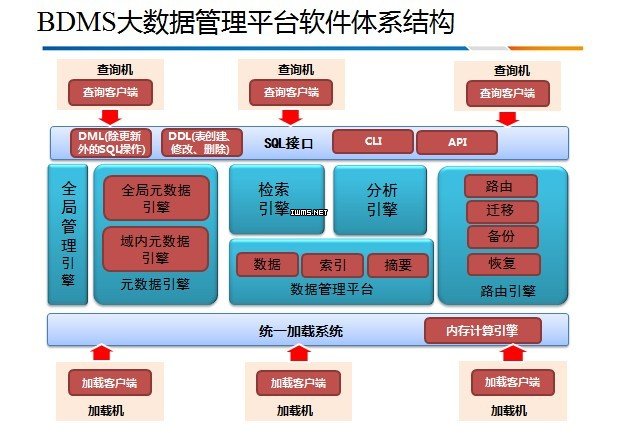
其中,可以通过管理引擎实现跨越数据管理。对外可以提供相应的DDL接口、DML的接口以及开发接口。
系统主要特色
Share-Nothing的分布式存储和计算架构
异构多源数据的组织管理:实现了结构化数据、非结构化文本及非结构化多媒体的统一存储管理
支持异构数据的统一SQL查询:支持对于结构化数据、非结构化文本的检索和分析,该检索和分析操作都可以通过SQL进行实现
丰富的数据访问和处理模式
高效的检索机制
异构多副本存储和恢复机制
跨域数据管理和检索:支持跨域部署,可以在多个物理地点建立多个数据中心,在此之上可以支持数据在数据中心之间进行移动,并且可以支持对于位于不同地域的数据进行全局检索和访问
应用场景
海量结构化记录管理
处理海量小文档管理和处理
面向异构数据的智能搜索和挖掘系统
成功案例
王树鹏介绍说这个系统已经有了成功的应用案例,是国家某部委大数据管理项目。这个系统的主要需求是:
大量信息记录,每天产生约40亿条(约4TB);
数据保留备份副本,记录数据保留半年;
可对数据进行精确、模糊查询及统计,结果秒级响应;
可批量导入结构化、非结构化数据;
最终达到的实施效果是:
采用分布式存储架构(3个元数据节点+115个存储节点);
数据规模超过5000亿 ,查询响应时间为秒级;
数据保留2个副本,保证数据安全;
系统可用容量约2PB。(文/周小璐 审校/仲浩)
作者:中立达资产评估
推荐内容 Recommended
- 版权评估为金融与文化架桥 10部剧版权=近亿元03-26
- 广州市知识产权质押融资风险赔偿基金开启“广03-08
- 普洱日报数字报01-31
- 市房地产交易大厅已评估事项实现率100%01-16
- 嘉兴专利权质押融资额达11.3亿元 居全省首位01-13
- 房地产估价师考试课程怎样选择?需要注意的问题有哪些?01-01
相关内容 Related
- 无形资产评估之非专利技术价值评估需要搜集哪11-26
- 非专利技术可以出资吗?有什么要求?11-26
- 康盛股份:拟以资产置换及支付现金方式购买资04-17
- 我国首个国家级知识产权评估认证中心成立04-16
- 华丽包装关联方无力偿还占用资金已用苗木资产抵债04-13
- 宝山区单位注销车辆回收过户手续怎么办04-05